

The binary search tree (BST) is a data structure that is much different from the other structures that we’ve gone over so far. Unlike stacks, queues, and lists, a BST’s struct is not a “straight-line”. Each node in a BST has a left and right child node.
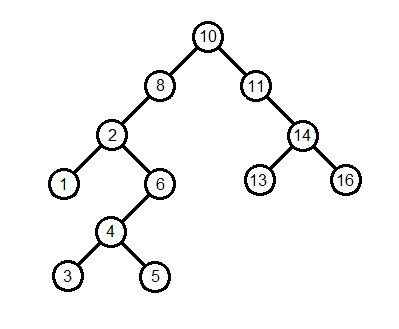
The BST above is a classic example of how BSTs work. “10” is the first node in the tree, and then all the other nodes are put in the tree. We’re going to make an unbalanced search tree today, and with the exception of deleting nodes, the location of nodes won’t change. A balanced search tree, which we won’t go over today, moves nodes around in tree to keep balance.
There are four main functions of a BST:
1. Insert. Due to the nature of BSTs, the insert function will create a new leaf (a bottom node of the tree).
2. Find functions (findMin, findMax, and contains). The find function is very similar to insert and will go down the tree until the value is found.
3. Remove. Remove deletes a node. This is most complicated function in a BST, as there are three different cases (we will go over these).
4. Print. There are three ways to print a BSTs that we will go over in this post. Each one prints the nodes out in a different order.
What makes a binary search tree so interesting is that the insert, find, and delete functions all have an average complexity of O(log n). When those functions are called, each iteration will reduce the number of “n” values that are left to search through by half, leading to O(log n) complexity. An easy example is search, where if we search for “14” in the BST above, the first iteration will take us to 11, removing the entire left half of the BST.
Now that BSTs have been introduced, let’s get into their implementation. It’s important to note that our BST won’t support duplicates, but that is definitely a feature you can add! We won’t go over the main and header files, most they are pretty close to the same as in the stacks and queues blog post. Check them out here: header and main.
1. Insert

You can see there are two insert functions. The first function is just calling the second function. This may seem a little confusing, but due to recursive calls, this makes it easier to call in main.
In insert, there are four cases. The first is our base case, we create a new node, assign the element value to our entry, then assign the left and right nodes to NULL. Our second and third cases are our recursive calls, these two move the the element farther down the tree. If the element is less than the value in the current branch, we send it left, but otherwise we’ll send it right. These two statements are what make BSTs interesting. Other data structures’ insert functions are linear, but the BST’s insert has multiple options.
2. findMin, findMax, and contains

These functions are all very similar, but each has a different purpose. Contains is a boolean function, and it goes through the tree to return “true” if the value is found. Functions findMin and findMax are essential “mirrored” functions. FindMin goes to the left node of each branch until the last left node is reached — this is the smallest value– and then this node is returned. FindMax goes through all the right nodes until the end is reached, then returns the largest value node.
3. Remove

Remove is easily the most complicated function of a Binary Search Tree. There are three separate cases for remove.
The first is when the node to be removed has no children. This is the easiest case, wherein we just delete the node.
The second case is when the node to be removed has one child. This case isn’t extremely difficult either, as we assign the child of the node to be removed to the original node’s location and then delete the old node. The last case is easily the most complicated, when the node has two children. In order for us to ensure the integrity of our BST, we must replace the node to be removed with a value that doesn’t how the binary search tree works. For us to do this, we need to pick the smallest node on the right child’s subtree. This is the only node that will ensure that the tree’s integrity isn’t changed. Here is where our findMin function is useful, we call findMin on the right node, and assign that value to the node to be deleted. We then “move” the node we found to the location of the node to be deleted, then we update the tree accordingly (as duplicates aren’t allowed).
4. Print Functions

Binary Search Trees can be printed out in three ways: PreOrder, PostOrder, and InOrder. All these functions have a “cout” call and two recursive calls, that is basically all that the print functions are.
PreOrder prints out the value of node before calling node->left and node->right. This prints out the left side of a tree, then the right side of the tree.
PostOrder prints out the values of node->left and node->right, then prints out the value of the node. Because this is a recursive call, it will print out all the leaf nodes, and then print out the branches.
InOrder is fairly simple. By printing out the node value in between calling the node->left and node->right, we print out the tree in order.